Homework 3
For any exercise where you’re writing code, insert a code chunk and make sure to label the chunk. Use a short and informative label. For any exercise where you’re creating a plot, make sure to label all axes, legends, etc. and give it an informative title. For any exercise where you’re including a description and/or interpretation, use full sentences. Make a commit at least after finishing each exercise, or better yet, more frequently. Push your work regularly to GitHub, and make sure all checks pass.
Question 1
Du Bois challenge. Recreate the following visualization by W.E.B. Du Bois on family budgets split by income classes for 150 families in Atlanta, Georgia. This visualization was originally created using ink and watercolors.
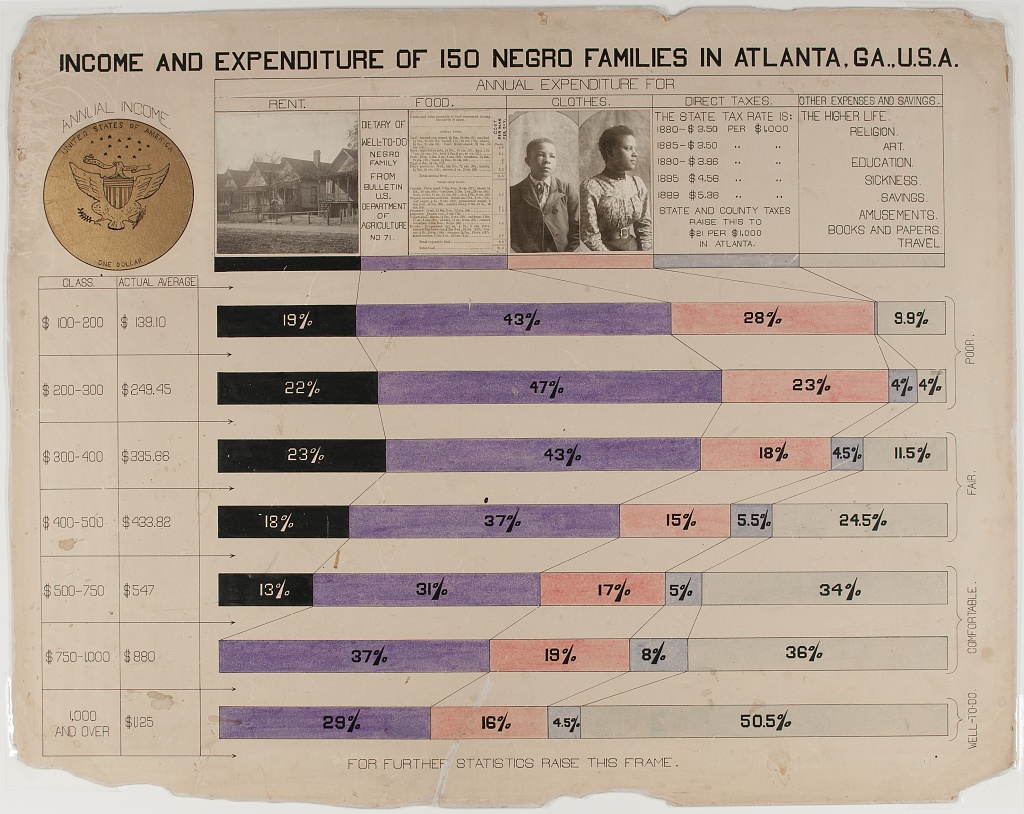
Notes for recreation:
Use the
data/income.csvas your starting point.You do not need to recreate (1) the plot title, (2) the dollar coin (the circle on top left) and the arched “Annual Income” text above it,
- the image and tiny text inside the legend box.
It is also ok if your y-axis isn’t a table like the one shown on the plot, but you want to make sure you do have the income ranges styled as closely as possible to the plot.
To change the background of the plot to match the background of the original visualization, look for an image of a “parchment paper” on a free image site like Pixabay (https://pixabay.com) and place the image file in your
images/folder and the image in the background of the plot.
Question 2
COVID survey - interpret. A survey was conducted on the attitudes and opinions towards COVID-19 vaccination held by medical and nursing students across the US. The data were collected by Pavan Shah, Giorgio Caturegli, Galen Shi, and Joshua Materi at Johns Hopkins School of Medicine. Huge thanks to Giorgio Caturegli for sharing the data with us! The following visualization was created based on the survey results.
Each facet in the visualization represents a response-explanatory variable combination. The response variables are in the columns and the explanatory variables are in the rows of the grid. For each response variable the survey takers indicated their level of agreement with the given statement. The responses were on a Likert scale: 1 - Strongly Agree, 2 - Somewhat Agree , 3 - Neither Agree Nor Disagree, 4 - Somewhat Disagree, 5 - Strongly Disagree.
Within each facet the data are represented with points (indicating the mean Likert score) and error bars spanning from 10th to 90th percentiles of the values of the response variable for each level of the explanatory variable. The first row is the only exception to this. This row of panes is noted as “All”, meaning that the it’s the distribution of each of the response variables without conditioning on any of the explanatory variables.
Your task for this question is to take a close look at this plot and interpret it. There is a lot going on here, which is customary for plots that go into scientific publications – they tend to be very information dense, for better or worse… As you interpret it, discuss if there are any results that agree or disagree with your intuition. There is a lot you can say, but we don’t need you to be exhaustive. Please provide three concrete examples.
Question 3
COVID survey - reconstruct. In this exercise you will reconstruct the plot provided in Exercise 2. You can find the raw data in data/survey.csv. Additional information on the survey can be found in data/covid_survey.pdf.
Load the data using
read_csv(). View the result and decide if any rows on top need to beskipped. If so, reload again with theskipargument. Print the dimensions of the resulting data frame withdim().Next, you’ll do a bit of data cleanup. Eliminate any rows where all values aside from
response_idare missing; these do not contain any useful information. Hint: There are many ways you can do this. One succinct way is using a combination offilter()andif_any()orif_all(). But feel free to use whatever works for your intuition, just make sure you’re only eliminating rows where all values (not any values!) aside fromresponse_idare missing. Print the dimensions of the resulting data frame withdim().Relabel the survey response values according to the information in
data/covid_survey.pdf. Peeking at the plot you’re working towards reconstructing can also be helpful to identify how exactly to recode the variables. Print the dimensions of the resulting data frame withdim().exp_already_vaxandexp_flu_vax: 0 - No, 1 - Yesexp_profession: 0 - Medical, 1 - Nursingexp_gender: 0 - Male, 1 - Female, 3 - Non-binary third gender, 4 - Prefer not to sayexp_race: 1 - American Indian / Alaskan Native, 2 - Asian, 3 - Black / African American, 4 - Native Hawaiian / Other Pacific Islander, 5 - Whiteexp_ethnicity: 1 - Hispanic / Latino, 2 - Non-Hispanic/Non-Latinoexp_age_bin: 0 - <20, 20 - 21-25, 25 - 26-30, 30 - >30
In our data we have response variables (the ones that start with
resp_:resp_safety,resp_confidence_science,resp_concern_safety,resp_feel_safe_at_work,resp_will_recommend, andresp_trust_info) and explanatory variables (the ones that start withexp_:exp_profession,exp_flu_vax,exp_gender,exp_race,exp_ethnicity,exp_age_bin, andexp_already_vax). For each response variable and each explanatory variable, we’re interested in how the values of the response variable change across values of the explanatory variable, so we calculate the 10th percentile, mean, and 90th percentile of each of the response variables for each level of each explanatory variable.
There are a variety of ways we can accomplish this. One of them is to pivot the data longer, twice (!), so that each row represents a combination of each response variable with explanatory variable and its level.
We provide you with the code for this task, you need to run the code and confirm that you get the same result. Make sure to print the resulting tibble to make comparison easier as you (and we!) check your work. Also write a sentence or two explaining what eachpivot_longer()statement is doing in this code.
covid_survey_longer <- covid_survey |>
pivot_longer(
cols = starts_with("exp_"),
names_to = "explanatory",
values_to = "explanatory_value"
) |>
filter(!is.na(explanatory_value)) |>
pivot_longer(
cols = starts_with("resp_"),
names_to = "response",
values_to = "response_value"
)covid_survey_longer# A tibble: 43,428 × 5
response_id explanatory explanatory_value response respon…¹
<dbl> <chr> <fct> <chr> <dbl>
1 1 exp_profession Nursing resp_safety 5
2 1 exp_profession Nursing resp_confidence_science 2
3 1 exp_profession Nursing resp_concern_safety 2
4 1 exp_profession Nursing resp_feel_safe_at_work 1
5 1 exp_profession Nursing resp_will_recommend 1
6 1 exp_profession Nursing resp_trust_info 1
7 1 exp_flu_vax Yes resp_safety 5
8 1 exp_flu_vax Yes resp_confidence_science 2
9 1 exp_flu_vax Yes resp_concern_safety 2
10 1 exp_flu_vax Yes resp_feel_safe_at_work 1
# … with 43,418 more rows, and abbreviated variable name ¹response_value- Group the data (
covid_survey_longer) byexplanatory,explanatory_value, andresponse, and then calculate the following summary statistics:mean: mean of theresponse_valuelow: 10th percentile of theresponse_valuehigh: 90th percentile of theresponse_valueName this new data framecovid_survey_summary_stats_by_group. It should look like the following:
covid_survey_summary_stats_by_group# A tibble: 126 × 6
explanatory explanatory_value response mean low high
<chr> <fct> <chr> <dbl> <dbl> <dbl>
1 exp_age_bin <20 resp_concern_safety 3.35 2 4.4
2 exp_age_bin <20 resp_confidence_science 1.65 1 2.4
3 exp_age_bin <20 resp_feel_safe_at_work 1.71 1 3.8
4 exp_age_bin <20 resp_safety 1.41 1 2
5 exp_age_bin <20 resp_trust_info 1.41 1 2
6 exp_age_bin <20 resp_will_recommend 1.35 1 1.8
7 exp_age_bin 21-25 resp_concern_safety 3.32 2 5
8 exp_age_bin 21-25 resp_confidence_science 1.31 1 2
9 exp_age_bin 21-25 resp_feel_safe_at_work 1.20 1 2
10 exp_age_bin 21-25 resp_safety 1.95 1 5
# … with 116 more rows- Now group the data (
covid_survey_longer) again, this time only byresponse, in order to calculate the same summary statistics for each response variable (mean, 10th percentile, and 90th percentile), not conditioned on the explanatory variables. Name this new data framecovid_survey_summary_stats_all. It should look like the following:
covid_survey_summary_stats_all# A tibble: 6 × 6
response mean low high explanatory explanatory_value
<chr> <dbl> <dbl> <dbl> <chr> <fct>
1 resp_concern_safety 3.28 1 5 All ""
2 resp_confidence_science 1.43 1 2 All ""
3 resp_feel_safe_at_work 1.36 1 2 All ""
4 resp_safety 2.03 1 5 All ""
5 resp_trust_info 1.40 1 2 All ""
6 resp_will_recommend 1.21 1 2 All "" - Bind the two data frames of summary statistics you created
covid_survey_summary_stats_allandcovid_survey_summary_stats_by_grouptogether by row. Name the resulting data framecovid_survey_summary_stats. It should look like the following:
covid_survey_summary_stats# A tibble: 132 × 6
response mean low high explanatory explanatory_value
<chr> <dbl> <dbl> <dbl> <chr> <fct>
1 resp_concern_safety 3.28 1 5 All ""
2 resp_confidence_science 1.43 1 2 All ""
3 resp_feel_safe_at_work 1.36 1 2 All ""
4 resp_safety 2.03 1 5 All ""
5 resp_trust_info 1.40 1 2 All ""
6 resp_will_recommend 1.21 1 2 All ""
7 resp_concern_safety 3.35 2 4.4 exp_age_bin "<20"
8 resp_confidence_science 1.65 1 2.4 exp_age_bin "<20"
9 resp_feel_safe_at_work 1.71 1 3.8 exp_age_bin "<20"
10 resp_safety 1.41 1 2 exp_age_bin "<20"
# … with 122 more rows- Using the data frame you created in the previous step (
covid_survey_summary_stats), recreate the visualization from Exercise 2. The following hints should help you along the way:- The survey prompts used for the response variables are as follows:
- “resp_safety” = “Based on my understanding, I believe the vaccine is safe”,
- “resp_confidence_science” = “I am confident in the scientific vetting process for the new COVID vaccines”,
- “resp_feel_safe_at_work” = “Getting the vaccine will make me feel safer at work”,
- “resp_will_recommend” = “I will recommend the vaccine to family, friends, and community members”,
- “resp_trust_info” = “I trust the information that I have received about the vaccines”,
- “resp_concern_safety” = “I am concerned about the safety and side effects of the vaccine”
- The variable names represented on the plot for the explanatory variables are as follows:
- “exp_age_bin” = “Age”,
- “exp_gender” = “Gender”,
- “exp_race” = “Race”,
- “exp_ethnicity” = “Ethnicity”,
- “exp_profession” = “Profession”,
- “exp_already_vax” = “Had COVID vaccine”,
- “exp_flu_vax” = “Had flu vaccine this year”
- The
facet_grid()function, which you will need to use to reconstruct this plot, has alabellerargument, which you can use to define how you want to add line breaks to facet labels. For example,labeller = labeller = labeller(explanatory = label_wrap_gen(15))places a line break after 15 characters on the labels of the facets defined by theexplanatoryvariable. - Don’t worry about matching the exact color for the background of the facet labels. But, if you want to match, the color is
gray90.
- The survey prompts used for the response variables are as follows:
Question 4
COVID survey - re-reconstruct. One way to evaluate if there’s anything misleading in the following plot would be to reconstruct it using quartiles different than the 10th and the 90th percentile. Repeating as little of the code you developed so far as possible, reconstruct the same plot where the ends of the error bars are the 25th and 75th percentiles of the distributions of each of the response variables conditioned on the levels of each of the explanatory variables. How does this plot compare to the plot you constructed in Exercise 2? Does it change any of your conclusions about the data? Explain your reasoning.
Question 5
COVID survey - another view. Create two bar charts of the Likert data for the six survey questions in from the plot in Exercise 2. This should be a single plot visualizing the percentages of each possible answer, with different questions on the y-axis. Use an appropriate color scale.
Create a diverging bar chart. Write alt text for your visualization as well.
Create a 100% bar chart. Write alt text for your visualization as well.
Comment on how the two charts from parts (a) and (b) compare with regards to comparability.